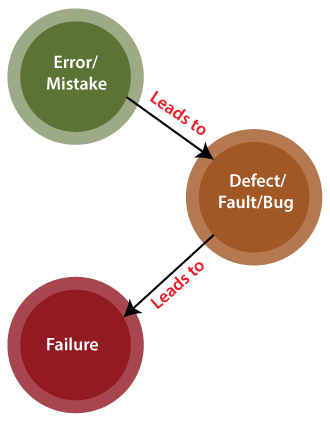
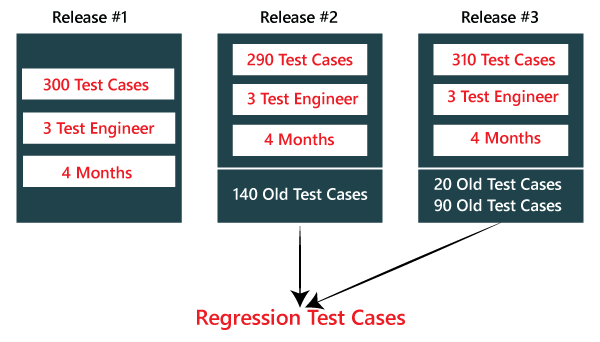
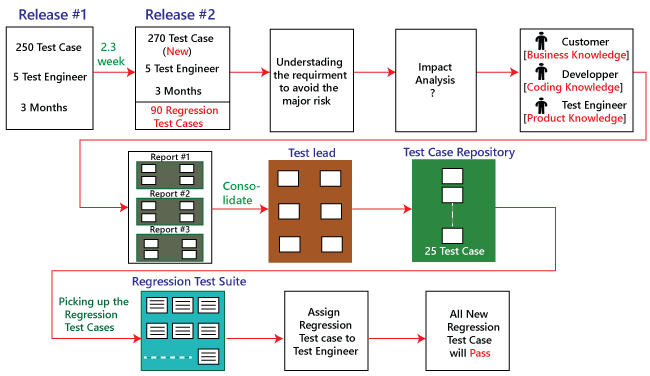
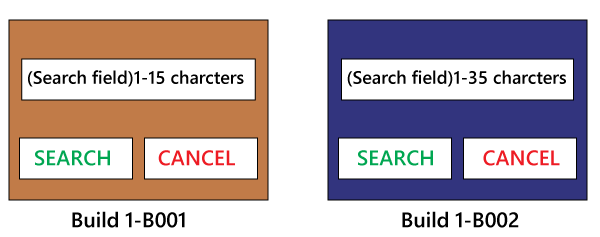
Differences between the Alpha testing and Beta testing are:
| Sr. No. | Alpha Testing | Beta Testing |
|---|---|---|
| 1. | Alpha testing performed by a team of highly skilled testers who are usually the internal employee of the organization. | Beta testing performed by clients or end-users in a real-time environment, who is not an employee of the organization. |
| 2. | Alpha testing performed at the developer’s site; it always needs a testing environment or lab environment. | Beta testing doesn’t need any lab environment or the testing environment; it is performed at a client’s location or end-user of the product. |
| 3. | Reliability or security testing not performed in-depth in alpha testing. | Reliability, security, and robustness checked during beta testing. |
| 4. | Alpha testing involves both white box and black-box techniques. | Beta testing uses only black-box testing. |
| 5. | Long execution cycles maybe require for alpha testing. | Only a few weeks are required for the execution of beta testing. |
| 6. | Critical issues or fixes can be identified by developers immediately in alpha testing. | Most of the issues or feedback is collecting from the beta testing will be implemented for the future versions of the product. |
| 7. | Alpha testing performed before the launch of the product into the market. | At the time of software product marketing. |
| 8. | Alpha testing focuses on the product’s quality before going to beta testing. | Beta testing concentrates on the quality of the product, but gathers users input on the product and ensures that the product is ready for real-time users. |
| 9. | Alpha testing performed nearly the end of the software development. | Beta testing is a final test before shipping a product to the customers. |
| 10. | Alpha testing is conducting in the presence of developers and the absence of end-users. | Beta testing reversed of alpha testing. |